erpl-rev: SAP Calls Out into DuckDB — 10 Million Rows a Minute

Picture the data team at a mid-sized manufacturer. Every night they need a fresh copy of the FI line items — BSEG and friends — in their lakehouse, where the analysts actually live: DuckDB, Parquet on object storage, the odd Iceberg table. The table is wide (hundreds of columns) and deep (tens of millions of rows), and the window is tight. The "official" answer is SLT: stand up a replication server, license it, configure the per-table settings in LTRS, babysit the queue. It works. It is also a lot of machinery — and budget — for what is, conceptually, "read this table fast and write it somewhere open."
I wanted to know how far the cheap path goes. SAP already exposes a perfectly good remote-function interface; DuckDB already ingests at memory bandwidth. What if ABAP just called out into DuckDB — no extension inside SAP, no SLT, no staging files — and we made the read fast enough to matter?
So I built it — two days, with Claude Code as the pair programmer. The result is erpl-rev, and on a throwaway SAP developer trial (single host, over loopback) it replicated 10,000,000 rows of a 400-column BSEG-shaped table in about a minute. It's an early release — a research prototype we're opening up, not an SLT replacement yet — but the numbers were enough to convince me the cheap path is real. Here is the story, the tools, and the numbers.
What erpl-rev is
erpl is a DuckDB extension that calls into SAP. erpl-rev is the inverse: a small standalone C++ server that registers a PROGRAM_ID at the SAP gateway, so your ABAP calls out to it —
CALL FUNCTION 'Z_DUCKDB_QUERY' DESTINATION 'ERPL_REV'
EXPORTING iv_sql = 'SELECT count(*) AS n FROM sflight'
IMPORTING ev_columns = lv_cols " JSON: [{name, type}, …]
ev_rows = lv_rows " JSON: [{…}, …]
ev_row_count = lv_cnt
ev_error = lv_err.
— and DuckDB runs behind the call. Two things, in equal measure:
- Query — send DuckDB SQL from ABAP and get typed rows back (or an ALV grid via an in-GUI console). Joins, window functions, Parquet scans over SAP data, and federation: join a SAP slice against a cloud Iceberg/Parquet/Postgres table in one statement.
- Replicate — bulk-load a table, CDS view (including
WITH PARAMETERS), or BW / HANA calculation view into a typed DuckDB table, a Parquet dataset, DuckLake, or an attached warehouse.
The two compose, and that is where it gets interesting. Replicate a SAP slice into DuckDB, then — in the same session — join it against data that never lived in SAP and hand the answer back to ABAP. Here are sales orders, freshly replicated, joined to a demand forecast sitting in Iceberg on S3, in one statement run from ABAP via Z_DUCKDB_QUERY (or the in-GUI console):
SELECT o.vbeln, o.kunnr, o.netwr, f.predicted_units
FROM vbak o -- SAP, replicated into DuckDB
JOIN iceberg_scan('s3://lake/demand_forecast') f -- never touched SAP
USING (matnr);
The rows come back to your ABAP program as a typed table. A cross-system join like that — live SAP data against an open-format table in the lakehouse — is something the SAP stack cannot do on its own.
The part that matters for the nightly-BSEG problem: there is nothing to install inside SAP. No DuckDB extension, no DDIC structures, no SLT/SDI/Data Services. You import a transport (a function group plus a report) and run the external server next to your gateway. Payloads travel as plain JSON / binary sXML over scalar RFC parameters, so the same generic interface carries any table, view, or query result.
How it got built: Claude Code with a real CLI
I did not write most of this by hand. I ran Claude Code in a terminal and gave it the tools a SAP developer actually uses — and the interesting part is which tools made the loop work.
The SAP system was a local A4H "ABAP Cloud Developer Trial" docker container, with the gateway registration ACL opened so an external server could register. The ABAP side — the function group, the Z_DUCKDB_* function modules, the replication classes, the end-user report — Claude wrote and deployed entirely through erpl-adt, our CLI for the SAP ADT REST API:
When it came time to measure, Claude wrote a small ABAP classrun, deployed it, ran it, and read the numbers straight back from the same shell — no Eclipse, no copy-paste:
$ uvx erpl-adt source write ZCL_ERPL_REV_PERF --file zcl_erpl_rev_perf.abap --activate
Activated: /sap/bc/adt/oo/classes/zcl_erpl_rev_perf
$ uvx erpl-adt object run ZCL_ERPL_REV_PERF
cols=50 part_col=BELNR rows=10000000
RESULT jobs=2 seconds=106 aggregate_rps=94340 per_worker_rps=47170
RESULT jobs=4 seconds=65 aggregate_rps=153846 per_worker_rps=38461
RESULT jobs=5 seconds=60 aggregate_rps=166667 per_worker_rps=33333
Those RESULT lines are the chart below — the closed loop is the whole trick. Claude writes ABAP, deploys it with erpl-adt, runs the classrun, reads the printed result, and decides what to change next. The C++ server side was the same idea against a different surface: edit, cmake --build, run the Catch2 suite against real DuckDB, read the output, iterate. When a number looked wrong, Claude could go measure instead of guess.
The toolset, deliberately small and orthogonal:
- Claude Code — the pair programmer, running real shell commands.
erpl-adt(viauvx, no install) — deploy and run ABAP from the terminal.- A local A4H docker trial — a disposable, real SAP system to build against.
- DuckDB 1.5.3 — the engine behind every call.
- The SAP NW RFC SDK — the registered-server plumbing.
- CMake + vcpkg, GitHub Actions — build and CI.
One file to ship
A SAP RFC server has an awkward dependency footprint: it links libsapnwrfc, which in turn dlopens a set of ICU libraries by name, plus we link libduckdb. The usual answer is "ship a folder and set LD_LIBRARY_PATH." For a tool you want people to actually try, that is friction.
So erpl-rev ships as one self-extracting binary per platform. The trick is borrowed from how erpl bundles its SDK, adapted for a standalone executable: the real server and all its runtime libraries are appended to a tiny launcher as a tar payload with a small footer. On first run the launcher locates itself, unpacks the payload to a per-version temp dir, points the loader at it, and execs the server. The user downloads a single file and runs it — the SAP SDK and DuckDB ride along inside.
Claude wrote that launcher to be portable in one pass (Linux, macOS, Windows), and the GitHub Actions release pipeline builds all three on every tag — pulling the proprietary SAP SDK from S3 via GitHub OIDC, bundling, and smoke-testing the result by running --help with no external libraries on the PATH. The macOS and Windows builds I could not test locally; CI built and verified them, and we fixed the two real portability issues (an MSVC <unistd.h> include, a Windows DLL-naming assumption) straight from the CI logs.
The numbers
The point of the exercise was throughput, so we measured it on the live trial. The source is ZWIDE_BSEG, a synthetic 400-column BSEG-shaped table filled to 10,000,000 rows; the run replicates a 50-column slice, partitioned on the document number (BELNR) across parallel background-job workers, over loopback.
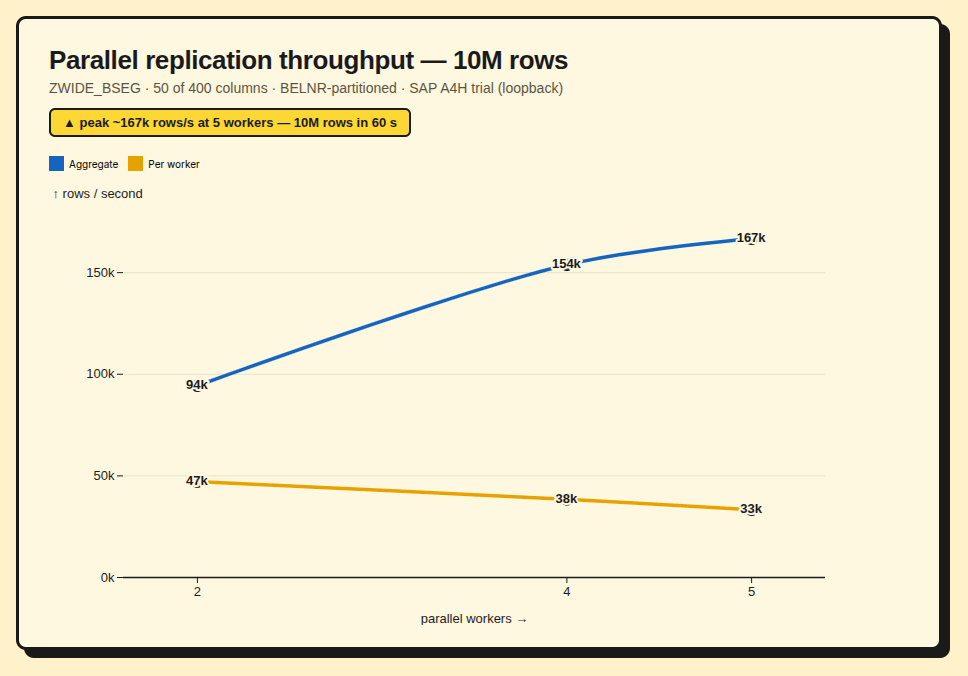
| Workers | Wall time | Aggregate | Per worker |
|---|---|---|---|
| 2 | 106 s | ~94,000 rows/s | ~47,000 rows/s |
| 4 | 65 s | ~154,000 rows/s | ~38,000 rows/s |
| 5 | 60 s | ~167,000 rows/s | ~33,000 rows/s |
Peak ~167,000 rows/s — ten million rows in a minute. A few things make that possible, and none of them is exotic:
- Bounded memory. Each worker reads its key range package-wise with keyset pagination (one fresh statement per page, default 50,000 rows), so peak RAM is set by the batch, not the table. A 100M-row load uses the same memory as a 100k-row one.
- Vectorized ingest. Each package lands via a DuckDB
Appenderinto a staging clone, then oneINSERT … SELECTwith casts — about 230× faster than the naive row-by-row path (the comparison lives intest/bench_ingest.cpp). - Parallel by background job. Workers stream disjoint key ranges concurrently into one target; the coordinator builds the primary key once at the end.
- Provably faithful. A diff harness compares the DuckDB target against the SAP source cell by cell (every row × column for SFLIGHT; per-row md5 for the wide table), plus a negative control that corrupts one value to prove the check actually detects it.
Two honest caveats. The scaling is sublinear — per-worker throughput tapers from 47k to 33k as workers contend for the SAP read side, and this trial caps out at five batch work processes. And these are loopback numbers on a single-host dev container; a real SAP-over-network deployment will differ. The conservative floor we quote is ≥10,000 rows/s per worker; the headline is what the hardware actually did.
Get it
erpl-rev is open source under the Business Source License 1.1, and the first release — v2026.06.03 — ships the self-extracting binaries:
| OS | Asset |
|---|---|
| Linux x86-64 | erpl-rev-linux-amd64.tar.gz |
| macOS arm64 | erpl-rev-macos-arm64.tar.gz |
| Windows x64 | erpl-rev-windows-amd64.zip |
# Linux
curl -LO https://github.com/DataZooDE/erpl-rev/releases/latest/download/erpl-rev-linux-amd64.tar.gz
tar xzf erpl-rev-linux-amd64.tar.gz
./erpl-rev-linux-amd64 --help # self-extracts the SAP SDK + DuckDB; nothing else to install
The README covers the one-time SAP side (import the transport, register the destination) and the security guide covers the gateway ACL, SNC, and the least-privilege RFC user you'll want in production.
It started as a question — how fast can the cheap path go? — and the answer turned out to be: fast enough that "just call out into DuckDB" is a real option for moving SAP data, not a toy. The repo is DataZooDE/erpl-rev. Tell me what you replicate with it.